
Unang Pagpapakilala noong 26, Hinagis ni Jensen Huang ang 2.5 Toneladang “Nuklear na Bomba” sa Entablado|CES2026

Ipakita ang orihinal
By:爱范儿
*May maliit na sorpresa sa dulo—isang video. Ito ang unang beses sa loob ng 5 taon na hindi naglabas ng consumer-grade graphics card ang NVIDIA sa CES. Buong kumpiyansang naglakad si CEO Jensen Huang papunta sa gitna ng entablado ng NVIDIA Live, suot pa rin ang makintab na jacket na gawa sa balat ng buwaya na sinuot niya noong nakaraang taon.  Hindi tulad ng nakaraang taon na may sariling keynote, abalang-abala si Jensen Huang ngayong 2026. Mula NVIDIA Live, lumipat siya sa Siemens Industrial AI na talakayan, at pagkatapos ay sa Lenovo TechWorld Conference—tatlong events sa loob ng 48 oras. Noong nakaraang beses, naglabas siya ng RTX 50 series graphics card sa CES. Ngayon naman, Physical AI, robotics, at isang 2.5 toneladang “ enterprise-level na nuclear bomb ” ang tunay na naging bida. Inilunsad ang Vera Rubin Computing Platform, mas marami kang bilhin, mas malaki ang matitipid mo Sa gitna ng event, nagdala mismo si Jensen Huang ng 2.5 toneladang AI server rack sa stage, na siyang naging highlight ng event: ang Vera Rubin Computing Platform, ipinangalan sa astronomer na nagdiskubre ng dark matter, na may iisang layunin lamang: Pabilisin ang AI training at dalhin agad ang susunod na henerasyon ng mga modelo.
Hindi tulad ng nakaraang taon na may sariling keynote, abalang-abala si Jensen Huang ngayong 2026. Mula NVIDIA Live, lumipat siya sa Siemens Industrial AI na talakayan, at pagkatapos ay sa Lenovo TechWorld Conference—tatlong events sa loob ng 48 oras. Noong nakaraang beses, naglabas siya ng RTX 50 series graphics card sa CES. Ngayon naman, Physical AI, robotics, at isang 2.5 toneladang “ enterprise-level na nuclear bomb ” ang tunay na naging bida. Inilunsad ang Vera Rubin Computing Platform, mas marami kang bilhin, mas malaki ang matitipid mo Sa gitna ng event, nagdala mismo si Jensen Huang ng 2.5 toneladang AI server rack sa stage, na siyang naging highlight ng event: ang Vera Rubin Computing Platform, ipinangalan sa astronomer na nagdiskubre ng dark matter, na may iisang layunin lamang: Pabilisin ang AI training at dalhin agad ang susunod na henerasyon ng mga modelo.  Karaniwan, may patakaran ang NVIDIA: bawat henerasyon ng produkto, 1–2 chips lang ang pinapalitan. Ngunit binago ito ng Vera Rubin—sabay-sabay na nire-design ang 6 na chips, at lahat ay nasa mass production na.
Karaniwan, may patakaran ang NVIDIA: bawat henerasyon ng produkto, 1–2 chips lang ang pinapalitan. Ngunit binago ito ng Vera Rubin—sabay-sabay na nire-design ang 6 na chips, at lahat ay nasa mass production na.
Bakit? Dahil bumabagal ang Moore’s Law, hindi na kaya ng tradisyunal na performance upgrades ang 10x growth ng AI models taon-taon. Kaya pinili ng NVIDIA ang “extreme collaborative design”—sabay-sabay ang inobasyon sa lahat ng chips at bawat layer ng platform. Ang anim na chips ay: 1. Vera CPU: - 88 na NVIDIA custom Olympus cores - May NVIDIA spatial multithreading technology, sumusuporta ng 176 threads - NVLink C2C bandwidth: 1.8 TB/s - System memory 1.5 TB (3X ng Grace) - LPDDR5X bandwidth 1.2 TB/s - 227 bilyong transistors
Ang anim na chips ay: 1. Vera CPU: - 88 na NVIDIA custom Olympus cores - May NVIDIA spatial multithreading technology, sumusuporta ng 176 threads - NVLink C2C bandwidth: 1.8 TB/s - System memory 1.5 TB (3X ng Grace) - LPDDR5X bandwidth 1.2 TB/s - 227 bilyong transistors  2. Rubin GPU: - 50 PFLOPS NVFP4 inference power, 5X ng Blackwell - 336 bilyong transistors, 1.6X ng Blackwell - May third-gen Transformer engine, kayang i-adjust ang precision batay sa pangangailangan ng Transformer models
2. Rubin GPU: - 50 PFLOPS NVFP4 inference power, 5X ng Blackwell - 336 bilyong transistors, 1.6X ng Blackwell - May third-gen Transformer engine, kayang i-adjust ang precision batay sa pangangailangan ng Transformer models  3. ConnectX-9 Network Card: - 800 Gb/s Ethernet na batay sa 200G PAM4 SerDes - Programmable RDMA at data path accelerator - CNSA at FIPS certified - 23 bilyong transistors
3. ConnectX-9 Network Card: - 800 Gb/s Ethernet na batay sa 200G PAM4 SerDes - Programmable RDMA at data path accelerator - CNSA at FIPS certified - 23 bilyong transistors  4. BlueField-4 DPU: - End-to-end engine na dinisenyo para sa bagong AI storage platform - 800G Gb/s DPU para sa SmartNIC at storage processor - 64-core Grace CPU na kasama ang ConnectX-9 - 126 bilyong transistors
4. BlueField-4 DPU: - End-to-end engine na dinisenyo para sa bagong AI storage platform - 800G Gb/s DPU para sa SmartNIC at storage processor - 64-core Grace CPU na kasama ang ConnectX-9 - 126 bilyong transistors  5. NVLink-6 Switch Chip: - Nagkokonekta ng 18 computing nodes, sinusuportahan hanggang 72 Rubin GPU na parang isang coordinated unit - Sa NVLink 6 architecture, bawat GPU ay may all-to-all communication bandwidth na 3.6 TB/s - Gumagamit ng 400G SerDes, may In-Network SHARP Collectives para sa collective communication sa loob ng network switch
5. NVLink-6 Switch Chip: - Nagkokonekta ng 18 computing nodes, sinusuportahan hanggang 72 Rubin GPU na parang isang coordinated unit - Sa NVLink 6 architecture, bawat GPU ay may all-to-all communication bandwidth na 3.6 TB/s - Gumagamit ng 400G SerDes, may In-Network SHARP Collectives para sa collective communication sa loob ng network switch  6. Spectrum-6 Optical Ethernet Switch Chip - 512 channels, bawat isa ay 200Gbps, para sa mas mabilis na data transfer - Integrated silicon photonics gamit ang TSMC COOP process - May copackaged optics interface - 352 bilyong transistors
6. Spectrum-6 Optical Ethernet Switch Chip - 512 channels, bawat isa ay 200Gbps, para sa mas mabilis na data transfer - Integrated silicon photonics gamit ang TSMC COOP process - May copackaged optics interface - 352 bilyong transistors  Sa pamamagitan ng malalim na integrasyon ng anim na chips, mas mataas ang overall performance ng Vera Rubin NVL72 system kumpara sa nakaraang Blackwell. Sa NVFP4 inference tasks, umabot ang chip sa 3.6 EFLOPS, 5X ng Blackwell architecture. Sa NVFP4 training, performance ay 2.5 EFLOPS, 3.5X na pagtaas. Sa storage capacity, may 54TB LPDDR5X memory ang NVL72—3X kumpara sa nakaraan. Ang HBM (High Bandwidth Memory) ay 20.7TB, 1.5X na pagtaas. Sa bandwidth, HBM4 ay 1.6 PB/s (2.8X na pagtaas), at Scale-Up bandwidth ay 260 TB/s (2X na pagtaas). Bagama’t napakalaki ng performance jump, 1.7X lang ang dinagdag sa bilang ng mga transistor, umabot sa 220 trilyon—patunay ng inobasyon sa semiconductor manufacturing.
Sa pamamagitan ng malalim na integrasyon ng anim na chips, mas mataas ang overall performance ng Vera Rubin NVL72 system kumpara sa nakaraang Blackwell. Sa NVFP4 inference tasks, umabot ang chip sa 3.6 EFLOPS, 5X ng Blackwell architecture. Sa NVFP4 training, performance ay 2.5 EFLOPS, 3.5X na pagtaas. Sa storage capacity, may 54TB LPDDR5X memory ang NVL72—3X kumpara sa nakaraan. Ang HBM (High Bandwidth Memory) ay 20.7TB, 1.5X na pagtaas. Sa bandwidth, HBM4 ay 1.6 PB/s (2.8X na pagtaas), at Scale-Up bandwidth ay 260 TB/s (2X na pagtaas). Bagama’t napakalaki ng performance jump, 1.7X lang ang dinagdag sa bilang ng mga transistor, umabot sa 220 trilyon—patunay ng inobasyon sa semiconductor manufacturing.  Sa engineering design, nagdala rin ng breakthrough ang Vera Rubin. Noon, kailangang ikabit ang 43 cables sa supercomputing nodes, 2 oras ang assembly, at madalas pa ring magkamali. Ngayon, walang cable ang Vera Rubin nodes—6 lang na liquid-cooling tubes, tapos sa loob ng 5 minuto. Mas matindi pa—ang likod ng rack ay may copper cables na halos 3.2 kilometrong haba, 5,000 cables para sa NVLink backbone na may 400Gbps speed. Sabi nga ni Jensen Huang: “Maaaring ilang daang libra ang bigat niyan; dapat matipuno kang CEO para kayanin ang trabahong ito.” Sa AI industry, oras ay pera. Isang mahalagang datos: para sanayin ang 10 trilyong parameter na modelo, 1/4 lang ng Blackwell systems ang kailangan ng Rubin; ang gastos sa pagbuo ng isang Token ay 1/10 ng Blackwell.
Sa engineering design, nagdala rin ng breakthrough ang Vera Rubin. Noon, kailangang ikabit ang 43 cables sa supercomputing nodes, 2 oras ang assembly, at madalas pa ring magkamali. Ngayon, walang cable ang Vera Rubin nodes—6 lang na liquid-cooling tubes, tapos sa loob ng 5 minuto. Mas matindi pa—ang likod ng rack ay may copper cables na halos 3.2 kilometrong haba, 5,000 cables para sa NVLink backbone na may 400Gbps speed. Sabi nga ni Jensen Huang: “Maaaring ilang daang libra ang bigat niyan; dapat matipuno kang CEO para kayanin ang trabahong ito.” Sa AI industry, oras ay pera. Isang mahalagang datos: para sanayin ang 10 trilyong parameter na modelo, 1/4 lang ng Blackwell systems ang kailangan ng Rubin; ang gastos sa pagbuo ng isang Token ay 1/10 ng Blackwell. 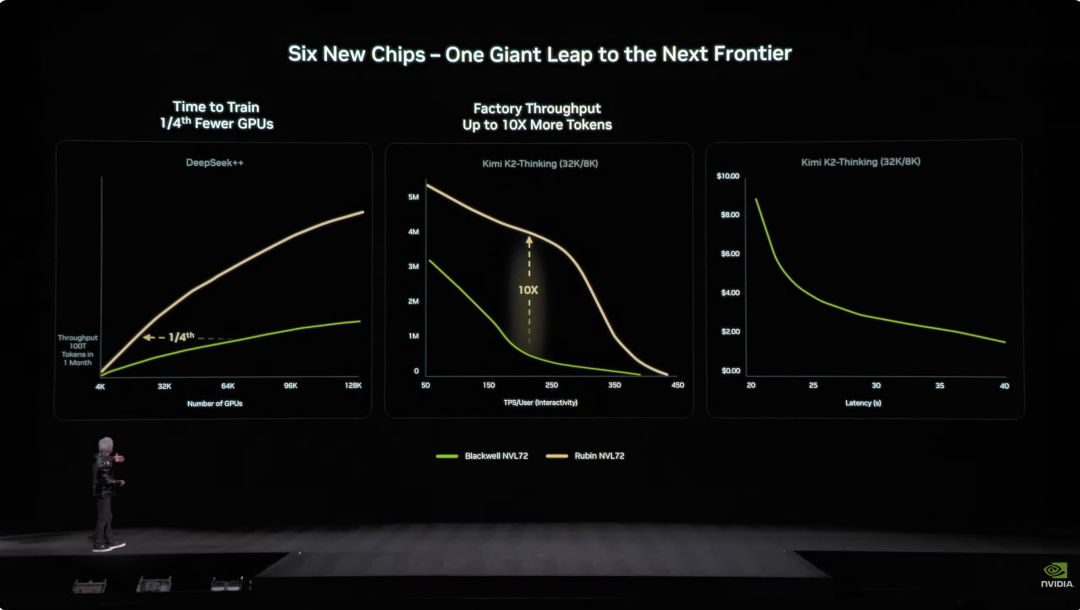 Bukod pa rito, kahit 2X na mas malakas ang power consumption ng Rubin kumpara sa Grace Blackwell, mas mataas pa rin ang performance gains: 5X sa inference, 3.5X sa training. Ang mas mahalaga, 10X ang pagtaas ng throughput (AI Tokens per watt per dollar) ng Rubin kumpara sa Blackwell. Para sa data center na nagkakahalaga ng $50 bilyon, doble ang revenue potential. Noon, ang pinakamalaking sakit ng ulo ng AI industry ay kakulangan ng context memory. Habang lumalaki ang conversation o model, kulang na kulang ang HBM memory para i-handle ang “KV Cache” (key-value cache)—ang work memory ng AI.
Bukod pa rito, kahit 2X na mas malakas ang power consumption ng Rubin kumpara sa Grace Blackwell, mas mataas pa rin ang performance gains: 5X sa inference, 3.5X sa training. Ang mas mahalaga, 10X ang pagtaas ng throughput (AI Tokens per watt per dollar) ng Rubin kumpara sa Blackwell. Para sa data center na nagkakahalaga ng $50 bilyon, doble ang revenue potential. Noon, ang pinakamalaking sakit ng ulo ng AI industry ay kakulangan ng context memory. Habang lumalaki ang conversation o model, kulang na kulang ang HBM memory para i-handle ang “KV Cache” (key-value cache)—ang work memory ng AI.  Itinulak ng NVIDIA ang Grace-Blackwell architecture para palakihin ang memory, pero kinulang pa rin. Ang solusyon ng Vera Rubin: mag-deploy ng BlueField-4 processors sa loob ng rack para pamahalaan ang KV Cache. Bawat node ay may 4 na BlueField-4, bawat isa ay may 150TB context memory, ipinapamahagi sa mga GPU. Bawat GPU ay may dagdag na 16TB memory (kadalasan 1TB lang ang built-in), at nananatili ang bandwidth na 200Gbps—hindi bumabagal ang bilis. Ngunit hindi sapat ang dami lang ng memory. Para magmukhang isang memory pool ang mga note sa libo-libong GPUs, dapat “malaki, mabilis, matatag” ang network—dito pumapasok ang Spectrum-X. Ang Spectrum-X ay ang kauna-unahang “designed for generative AI” end-to-end Ethernet network platform ng NVIDIA. Pinakabagong henerasyon nito ay gamit ang TSMC COOP process, integrated silicon photonics, at 512 channels × 200Gbps speed. Nagkwenta si Jensen Huang: $50 bilyon ang halaga ng isang gigawatt data center, at kayang magdala ng 25% throughput boost ang Spectrum-X—parang $5 bilyon na savings. “Pwede mong sabihing halos libre na ang network system na ito.” Sa usaping seguridad, sumusuporta ang Vera Rubin ng Confidential Computing. Lahat ng data—transmission, storage, computation—ay encrypted, kasama na ang mga PCIe channel, NVLink, CPU-GPU communications, at lahat ng bus. Kaya pwedeng-pwede mag-deploy ng modelo sa external system ang mga kumpanya, walang takot sa data leakage. DeepSeek gumulat sa mundo; open source at agents ang AI mainstream Matapos ang main event, balikan natin ang simula ng speech. Pag-akyat pa lang ni Jensen Huang sa stage, nagbanggit na siya ng nakakagulat na numero: sa nakalipas na dekada, halos $10 trilyon na computing resources ang minodernisa. Ngunit higit pa ito sa hardware upgrade, mas paradigm shift sa software. Partikular siyang tumukoy sa agentic AI models tulad ng Cursor, na nagbago ng programming approach sa loob ng NVIDIA.
Itinulak ng NVIDIA ang Grace-Blackwell architecture para palakihin ang memory, pero kinulang pa rin. Ang solusyon ng Vera Rubin: mag-deploy ng BlueField-4 processors sa loob ng rack para pamahalaan ang KV Cache. Bawat node ay may 4 na BlueField-4, bawat isa ay may 150TB context memory, ipinapamahagi sa mga GPU. Bawat GPU ay may dagdag na 16TB memory (kadalasan 1TB lang ang built-in), at nananatili ang bandwidth na 200Gbps—hindi bumabagal ang bilis. Ngunit hindi sapat ang dami lang ng memory. Para magmukhang isang memory pool ang mga note sa libo-libong GPUs, dapat “malaki, mabilis, matatag” ang network—dito pumapasok ang Spectrum-X. Ang Spectrum-X ay ang kauna-unahang “designed for generative AI” end-to-end Ethernet network platform ng NVIDIA. Pinakabagong henerasyon nito ay gamit ang TSMC COOP process, integrated silicon photonics, at 512 channels × 200Gbps speed. Nagkwenta si Jensen Huang: $50 bilyon ang halaga ng isang gigawatt data center, at kayang magdala ng 25% throughput boost ang Spectrum-X—parang $5 bilyon na savings. “Pwede mong sabihing halos libre na ang network system na ito.” Sa usaping seguridad, sumusuporta ang Vera Rubin ng Confidential Computing. Lahat ng data—transmission, storage, computation—ay encrypted, kasama na ang mga PCIe channel, NVLink, CPU-GPU communications, at lahat ng bus. Kaya pwedeng-pwede mag-deploy ng modelo sa external system ang mga kumpanya, walang takot sa data leakage. DeepSeek gumulat sa mundo; open source at agents ang AI mainstream Matapos ang main event, balikan natin ang simula ng speech. Pag-akyat pa lang ni Jensen Huang sa stage, nagbanggit na siya ng nakakagulat na numero: sa nakalipas na dekada, halos $10 trilyon na computing resources ang minodernisa. Ngunit higit pa ito sa hardware upgrade, mas paradigm shift sa software. Partikular siyang tumukoy sa agentic AI models tulad ng Cursor, na nagbago ng programming approach sa loob ng NVIDIA. 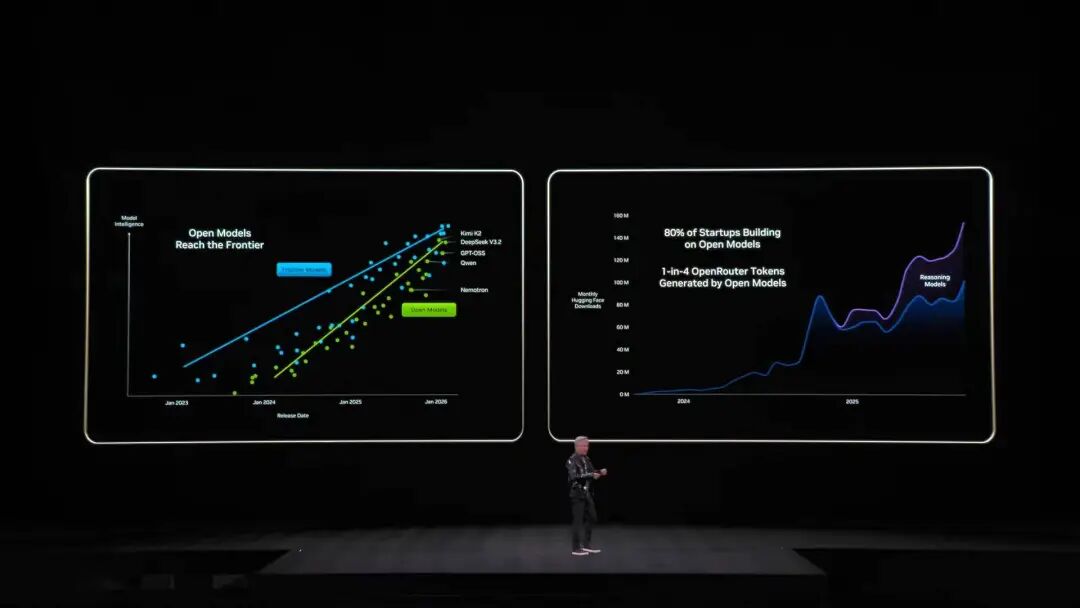 Pinaka-nagpasaya sa audience ay ang mataas niyang papuri sa open source community. Ayon kay Jensen Huang, ang breakthrough ng DeepSeek V1 noong nakaraang taon ay nagpakita sa mundo ng unang open source inference system, na siyang naging mitsa ng industry boom. Sa PPT, pamilyar nating mga Chinese player na Kimi k2 at DeepSeek V3.2 ang nangunguna sa open source. Sabi niya, kahit na-late ng anim na buwan ang open source models kumpara sa pinakabagong proprietary models, kada anim na buwan ay may bagong modelong lumalabas. Dahil sa bilis ng iteration, ayaw magpahuli ng startups, tech giants, o researchers—pati na ang NVIDIA. Kaya naman, hindi lang sila nagbebenta ng “pala” o graphics card; binuo rin ng NVIDIA ang multi-billion dollar DGX Cloud supercomputer, at nag-develop ng advanced models gaya ng La Proteina (protein synthesis) at OpenFold 3.
Pinaka-nagpasaya sa audience ay ang mataas niyang papuri sa open source community. Ayon kay Jensen Huang, ang breakthrough ng DeepSeek V1 noong nakaraang taon ay nagpakita sa mundo ng unang open source inference system, na siyang naging mitsa ng industry boom. Sa PPT, pamilyar nating mga Chinese player na Kimi k2 at DeepSeek V3.2 ang nangunguna sa open source. Sabi niya, kahit na-late ng anim na buwan ang open source models kumpara sa pinakabagong proprietary models, kada anim na buwan ay may bagong modelong lumalabas. Dahil sa bilis ng iteration, ayaw magpahuli ng startups, tech giants, o researchers—pati na ang NVIDIA. Kaya naman, hindi lang sila nagbebenta ng “pala” o graphics card; binuo rin ng NVIDIA ang multi-billion dollar DGX Cloud supercomputer, at nag-develop ng advanced models gaya ng La Proteina (protein synthesis) at OpenFold 3.  Saklaw ng open source model ecosystem ng NVIDIA ang biomedicine, Physical AI, agent models, robotics, at autonomous driving. Bilang highlight, maraming open source models mula sa NVIDIA Nemotron family ang ipinakilala. Saklaw nito ang voice, multimodal, retrieval-augmented generation, at security—at ayon kay Jensen, nangunguna ang Nemotron open source models sa maraming benchmark at ginagamit ng maraming kumpanya. Ano ang Physical AI? Dose-dosenang models ang inilunsad agad Kung ang large language models ay para sa digital world, malinaw na ang susunod na ambisyon ng NVIDIA ay dominahin ang “physical world.” Sabi ni Jensen, kailangan matutong umunawa ng AI ng physical laws at mabuhay sa totoong mundo, kung saan napaka-rare ng data. Bukod sa Nemotron agent open source models, inilatag niya ang core architecture ng Physical AI gamit ang “tatlong computer.”
Saklaw ng open source model ecosystem ng NVIDIA ang biomedicine, Physical AI, agent models, robotics, at autonomous driving. Bilang highlight, maraming open source models mula sa NVIDIA Nemotron family ang ipinakilala. Saklaw nito ang voice, multimodal, retrieval-augmented generation, at security—at ayon kay Jensen, nangunguna ang Nemotron open source models sa maraming benchmark at ginagamit ng maraming kumpanya. Ano ang Physical AI? Dose-dosenang models ang inilunsad agad Kung ang large language models ay para sa digital world, malinaw na ang susunod na ambisyon ng NVIDIA ay dominahin ang “physical world.” Sabi ni Jensen, kailangan matutong umunawa ng AI ng physical laws at mabuhay sa totoong mundo, kung saan napaka-rare ng data. Bukod sa Nemotron agent open source models, inilatag niya ang core architecture ng Physical AI gamit ang “tatlong computer.” 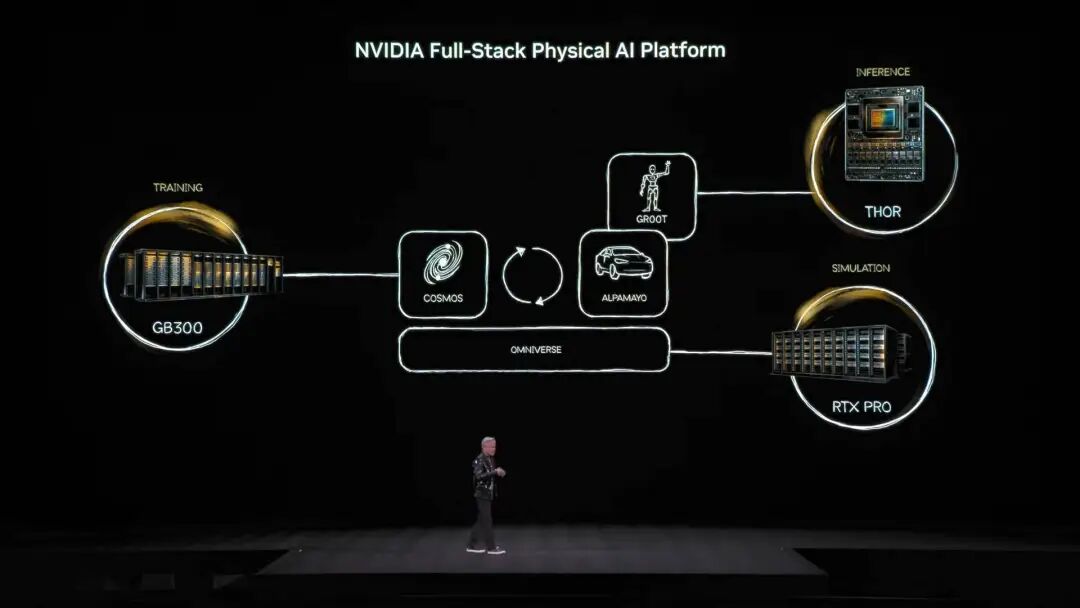
Training computer—ito ang karaniwang computer na may training-grade graphics cards, gaya ng GB300 architecture.
Inference computer—“cerebellum” sa robot o kotse na gumagana sa edge, para sa real-time execution.
Simulation computer—kasama ang Omniverse at Cosmos, nagbibigay ng virtual training environment para matutunan ng AI ang physical feedback. Kaya ng Cosmos system lumikha ng napakaraming training environments para sa Physical AI Batay sa arkitekturang ito, opisyal na inilunsad ni Jensen Huang ang Alpamayo, ang pinakaunang autonomous driving model sa mundo na may kakayahang mag-isip at mag-reason.
Kaya ng Cosmos system lumikha ng napakaraming training environments para sa Physical AI Batay sa arkitekturang ito, opisyal na inilunsad ni Jensen Huang ang Alpamayo, ang pinakaunang autonomous driving model sa mundo na may kakayahang mag-isip at mag-reason.  Iba ito sa tradisyunal na autonomous driving—end-to-end training ang Alpamayo. Ang breakthrough nito: nasolusyunan ang “long tail problem” ng self-driving. Sa harap ng hindi pa nakikitang complex na daan, hindi lang basta nag-eexecute ng code si Alpamayo—kaya nitong mag-reason parang tao. “Sasabihin nito kung ano’ng susunod na gagawin, at bakit iyon ang naging desisyon.” Sa demo, natural ang driving ng kotse, kaya nitong hatiin ang complex na sitwasyon at lutasin gamit ang basic common sense. Hindi lang ito demo—opisyal na inanunsyo ni Jensen na ang Mercedes CLA na may Alpamayo tech stack ay ilulunsad ngayong Q1 sa US, at kasunod sa Europe at Asia.
Iba ito sa tradisyunal na autonomous driving—end-to-end training ang Alpamayo. Ang breakthrough nito: nasolusyunan ang “long tail problem” ng self-driving. Sa harap ng hindi pa nakikitang complex na daan, hindi lang basta nag-eexecute ng code si Alpamayo—kaya nitong mag-reason parang tao. “Sasabihin nito kung ano’ng susunod na gagawin, at bakit iyon ang naging desisyon.” Sa demo, natural ang driving ng kotse, kaya nitong hatiin ang complex na sitwasyon at lutasin gamit ang basic common sense. Hindi lang ito demo—opisyal na inanunsyo ni Jensen na ang Mercedes CLA na may Alpamayo tech stack ay ilulunsad ngayong Q1 sa US, at kasunod sa Europe at Asia.  Itinuring ng NCAP na pinakaligtas na kotse sa mundo ang modelong ito, dahil sa unique na “dual safety stack” ng NVIDIA. Kapag kulang sa kumpiyansa ang end-to-end AI, awtomatikong lilipat sa tradisyunal na safety mode para tiyak ang seguridad. Sa event, ipinakita rin ni Jensen Huang ang robot strategy ng NVIDIA.
Itinuring ng NCAP na pinakaligtas na kotse sa mundo ang modelong ito, dahil sa unique na “dual safety stack” ng NVIDIA. Kapag kulang sa kumpiyansa ang end-to-end AI, awtomatikong lilipat sa tradisyunal na safety mode para tiyak ang seguridad. Sa event, ipinakita rin ni Jensen Huang ang robot strategy ng NVIDIA. 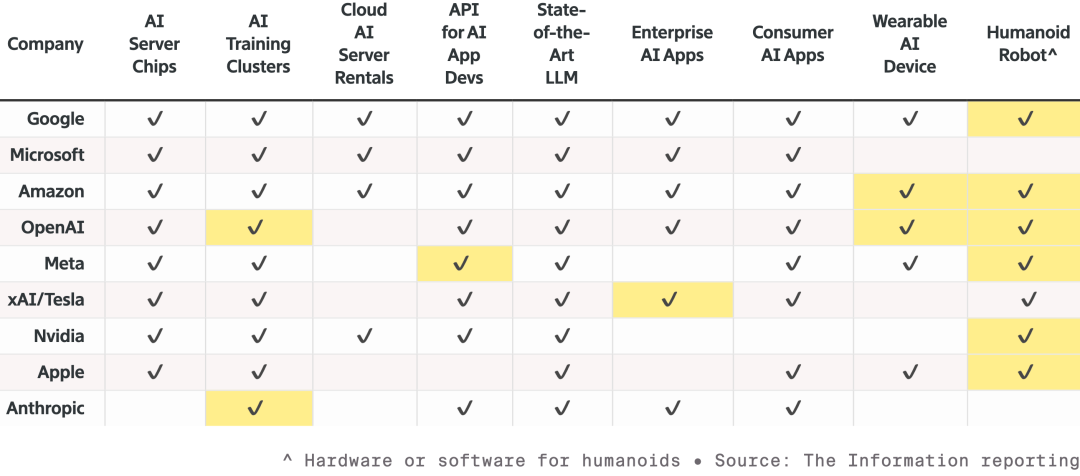 Kompetisyon ng siyam na top AI at hardware manufacturers, palawak nang palawak ang produkto, lalo na sa robotics. Ang highlighted cells ay mga bagong produkto buhat noong nakaraang taon. Lahat ng robot ay gagamit ng Jetson mini computer, matututo sa Isaac simulator sa Omniverse platform. At pinagsasama ng NVIDIA ang teknolohiyang ito sa Synopsys, Cadence, Siemens, at iba pang industrial systems.
Kompetisyon ng siyam na top AI at hardware manufacturers, palawak nang palawak ang produkto, lalo na sa robotics. Ang highlighted cells ay mga bagong produkto buhat noong nakaraang taon. Lahat ng robot ay gagamit ng Jetson mini computer, matututo sa Isaac simulator sa Omniverse platform. At pinagsasama ng NVIDIA ang teknolohiyang ito sa Synopsys, Cadence, Siemens, at iba pang industrial systems.  Inanyayahan ni Jensen Huang ang Boston Dynamics, Agility, at iba pang humanoid at quadruped robots sa stage—binigyang-diin niya na ang pinakamalaking robot ay mismong pabrika. Mula sa pinaka-basic, ang pangarap ng NVIDIA ay sa hinaharap, chip design, system design, at factory simulation ay pabilisin ng Physical AI ng NVIDIA. Sa event, nagpakitang-gilas pa ang Disney robots, at nagbiro si Jensen sa mga cute na robot: “Didesenyo kayo sa computer, gagawin sa computer, at bago pa maka-experience ng gravity, matetest at mava-validate na kayo sa computer.”
Inanyayahan ni Jensen Huang ang Boston Dynamics, Agility, at iba pang humanoid at quadruped robots sa stage—binigyang-diin niya na ang pinakamalaking robot ay mismong pabrika. Mula sa pinaka-basic, ang pangarap ng NVIDIA ay sa hinaharap, chip design, system design, at factory simulation ay pabilisin ng Physical AI ng NVIDIA. Sa event, nagpakitang-gilas pa ang Disney robots, at nagbiro si Jensen sa mga cute na robot: “Didesenyo kayo sa computer, gagawin sa computer, at bago pa maka-experience ng gravity, matetest at mava-validate na kayo sa computer.”  Kung hindi mo alam na si Jensen Huang ang nagsalita, aakalain mong event ito ng isang model developer. Sa kabila ng AI bubble debate at paghina ng Moore’s Law, kailangan ni Jensen na ipakita kung ano nga ba ang kayang gawin ng AI para mapanatili ang kumpiyansa natin dito. Bukod sa pagpapakilala ng Vera Rubin AI supercomputing platform, naglaan din siya ng malaking effort sa applications at software para makita natin ang konkreto at diretsong pagbabago na pwedeng dalhin ng AI. Tulad ng sinabi niya, dati para sa virtual world ang chip nila, pero ngayon, sila mismo ang humaharap at nagpapakita—nakatutok sa physical AI, gaya ng autonomous driving at humanoid robots, para sumabak sa mas matinding kompetisyon sa totoong mundo. Dahil sa huli, kapag sumiklab ang digmaan, tuloy-tuloy ang benta ng armas. *Panghuli, narito ang easter egg na video: Dahil bitin ang oras sa CES, maraming slides si Jensen Huang na di naipakita. Kaya naman, ginawa niyang nakakatawang short film ang mga hindi naipakitang PPT. Panoorin sa ibaba⬇️
Kung hindi mo alam na si Jensen Huang ang nagsalita, aakalain mong event ito ng isang model developer. Sa kabila ng AI bubble debate at paghina ng Moore’s Law, kailangan ni Jensen na ipakita kung ano nga ba ang kayang gawin ng AI para mapanatili ang kumpiyansa natin dito. Bukod sa pagpapakilala ng Vera Rubin AI supercomputing platform, naglaan din siya ng malaking effort sa applications at software para makita natin ang konkreto at diretsong pagbabago na pwedeng dalhin ng AI. Tulad ng sinabi niya, dati para sa virtual world ang chip nila, pero ngayon, sila mismo ang humaharap at nagpapakita—nakatutok sa physical AI, gaya ng autonomous driving at humanoid robots, para sumabak sa mas matinding kompetisyon sa totoong mundo. Dahil sa huli, kapag sumiklab ang digmaan, tuloy-tuloy ang benta ng armas. *Panghuli, narito ang easter egg na video: Dahil bitin ang oras sa CES, maraming slides si Jensen Huang na di naipakita. Kaya naman, ginawa niyang nakakatawang short film ang mga hindi naipakitang PPT. Panoorin sa ibaba⬇️ 
Hindi tulad ng nakaraang taon na may sariling keynote, abalang-abala si Jensen Huang ngayong 2026. Mula NVIDIA Live, lumipat siya sa Siemens Industrial AI na talakayan, at pagkatapos ay sa Lenovo TechWorld Conference—tatlong events sa loob ng 48 oras. Noong nakaraang beses, naglabas siya ng RTX 50 series graphics card sa CES. Ngayon naman, Physical AI, robotics, at isang 2.5 toneladang “ enterprise-level na nuclear bomb ” ang tunay na naging bida. Inilunsad ang Vera Rubin Computing Platform, mas marami kang bilhin, mas malaki ang matitipid mo Sa gitna ng event, nagdala mismo si Jensen Huang ng 2.5 toneladang AI server rack sa stage, na siyang naging highlight ng event: ang Vera Rubin Computing Platform, ipinangalan sa astronomer na nagdiskubre ng dark matter, na may iisang layunin lamang: Pabilisin ang AI training at dalhin agad ang susunod na henerasyon ng mga modelo. Karaniwan, may patakaran ang NVIDIA: bawat henerasyon ng produkto, 1–2 chips lang ang pinapalitan. Ngunit binago ito ng Vera Rubin—sabay-sabay na nire-design ang 6 na chips, at lahat ay nasa mass production na. Bakit? Dahil bumabagal ang Moore’s Law, hindi na kaya ng tradisyunal na performance upgrades ang 10x growth ng AI models taon-taon. Kaya pinili ng NVIDIA ang “extreme collaborative design”—sabay-sabay ang inobasyon sa lahat ng chips at bawat layer ng platform.
Ang anim na chips ay: 1. Vera CPU: - 88 na NVIDIA custom Olympus cores - May NVIDIA spatial multithreading technology, sumusuporta ng 176 threads - NVLink C2C bandwidth: 1.8 TB/s - System memory 1.5 TB (3X ng Grace) - LPDDR5X bandwidth 1.2 TB/s - 227 bilyong transistors 2. Rubin GPU: - 50 PFLOPS NVFP4 inference power, 5X ng Blackwell - 336 bilyong transistors, 1.6X ng Blackwell - May third-gen Transformer engine, kayang i-adjust ang precision batay sa pangangailangan ng Transformer models 3. ConnectX-9 Network Card: - 800 Gb/s Ethernet na batay sa 200G PAM4 SerDes - Programmable RDMA at data path accelerator - CNSA at FIPS certified - 23 bilyong transistors 4. BlueField-4 DPU: - End-to-end engine na dinisenyo para sa bagong AI storage platform - 800G Gb/s DPU para sa SmartNIC at storage processor - 64-core Grace CPU na kasama ang ConnectX-9 - 126 bilyong transistors 5. NVLink-6 Switch Chip: - Nagkokonekta ng 18 computing nodes, sinusuportahan hanggang 72 Rubin GPU na parang isang coordinated unit - Sa NVLink 6 architecture, bawat GPU ay may all-to-all communication bandwidth na 3.6 TB/s - Gumagamit ng 400G SerDes, may In-Network SHARP Collectives para sa collective communication sa loob ng network switch 6. Spectrum-6 Optical Ethernet Switch Chip - 512 channels, bawat isa ay 200Gbps, para sa mas mabilis na data transfer - Integrated silicon photonics gamit ang TSMC COOP process - May copackaged optics interface - 352 bilyong transistors Sa pamamagitan ng malalim na integrasyon ng anim na chips, mas mataas ang overall performance ng Vera Rubin NVL72 system kumpara sa nakaraang Blackwell. Sa NVFP4 inference tasks, umabot ang chip sa 3.6 EFLOPS, 5X ng Blackwell architecture. Sa NVFP4 training, performance ay 2.5 EFLOPS, 3.5X na pagtaas. Sa storage capacity, may 54TB LPDDR5X memory ang NVL72—3X kumpara sa nakaraan. Ang HBM (High Bandwidth Memory) ay 20.7TB, 1.5X na pagtaas. Sa bandwidth, HBM4 ay 1.6 PB/s (2.8X na pagtaas), at Scale-Up bandwidth ay 260 TB/s (2X na pagtaas). Bagama’t napakalaki ng performance jump, 1.7X lang ang dinagdag sa bilang ng mga transistor, umabot sa 220 trilyon—patunay ng inobasyon sa semiconductor manufacturing. Sa engineering design, nagdala rin ng breakthrough ang Vera Rubin. Noon, kailangang ikabit ang 43 cables sa supercomputing nodes, 2 oras ang assembly, at madalas pa ring magkamali. Ngayon, walang cable ang Vera Rubin nodes—6 lang na liquid-cooling tubes, tapos sa loob ng 5 minuto. Mas matindi pa—ang likod ng rack ay may copper cables na halos 3.2 kilometrong haba, 5,000 cables para sa NVLink backbone na may 400Gbps speed. Sabi nga ni Jensen Huang: “Maaaring ilang daang libra ang bigat niyan; dapat matipuno kang CEO para kayanin ang trabahong ito.” Sa AI industry, oras ay pera. Isang mahalagang datos: para sanayin ang 10 trilyong parameter na modelo, 1/4 lang ng Blackwell systems ang kailangan ng Rubin; ang gastos sa pagbuo ng isang Token ay 1/10 ng Blackwell. Bukod pa rito, kahit 2X na mas malakas ang power consumption ng Rubin kumpara sa Grace Blackwell, mas mataas pa rin ang performance gains: 5X sa inference, 3.5X sa training. Ang mas mahalaga, 10X ang pagtaas ng throughput (AI Tokens per watt per dollar) ng Rubin kumpara sa Blackwell. Para sa data center na nagkakahalaga ng $50 bilyon, doble ang revenue potential. Noon, ang pinakamalaking sakit ng ulo ng AI industry ay kakulangan ng context memory. Habang lumalaki ang conversation o model, kulang na kulang ang HBM memory para i-handle ang “KV Cache” (key-value cache)—ang work memory ng AI. Itinulak ng NVIDIA ang Grace-Blackwell architecture para palakihin ang memory, pero kinulang pa rin. Ang solusyon ng Vera Rubin: mag-deploy ng BlueField-4 processors sa loob ng rack para pamahalaan ang KV Cache. Bawat node ay may 4 na BlueField-4, bawat isa ay may 150TB context memory, ipinapamahagi sa mga GPU. Bawat GPU ay may dagdag na 16TB memory (kadalasan 1TB lang ang built-in), at nananatili ang bandwidth na 200Gbps—hindi bumabagal ang bilis. Ngunit hindi sapat ang dami lang ng memory. Para magmukhang isang memory pool ang mga note sa libo-libong GPUs, dapat “malaki, mabilis, matatag” ang network—dito pumapasok ang Spectrum-X. Ang Spectrum-X ay ang kauna-unahang “designed for generative AI” end-to-end Ethernet network platform ng NVIDIA. Pinakabagong henerasyon nito ay gamit ang TSMC COOP process, integrated silicon photonics, at 512 channels × 200Gbps speed. Nagkwenta si Jensen Huang: $50 bilyon ang halaga ng isang gigawatt data center, at kayang magdala ng 25% throughput boost ang Spectrum-X—parang $5 bilyon na savings. “Pwede mong sabihing halos libre na ang network system na ito.” Sa usaping seguridad, sumusuporta ang Vera Rubin ng Confidential Computing. Lahat ng data—transmission, storage, computation—ay encrypted, kasama na ang mga PCIe channel, NVLink, CPU-GPU communications, at lahat ng bus. Kaya pwedeng-pwede mag-deploy ng modelo sa external system ang mga kumpanya, walang takot sa data leakage. DeepSeek gumulat sa mundo; open source at agents ang AI mainstream Matapos ang main event, balikan natin ang simula ng speech. Pag-akyat pa lang ni Jensen Huang sa stage, nagbanggit na siya ng nakakagulat na numero: sa nakalipas na dekada, halos $10 trilyon na computing resources ang minodernisa. Ngunit higit pa ito sa hardware upgrade, mas paradigm shift sa software. Partikular siyang tumukoy sa agentic AI models tulad ng Cursor, na nagbago ng programming approach sa loob ng NVIDIA. Pinaka-nagpasaya sa audience ay ang mataas niyang papuri sa open source community. Ayon kay Jensen Huang, ang breakthrough ng DeepSeek V1 noong nakaraang taon ay nagpakita sa mundo ng unang open source inference system, na siyang naging mitsa ng industry boom. Sa PPT, pamilyar nating mga Chinese player na Kimi k2 at DeepSeek V3.2 ang nangunguna sa open source. Sabi niya, kahit na-late ng anim na buwan ang open source models kumpara sa pinakabagong proprietary models, kada anim na buwan ay may bagong modelong lumalabas. Dahil sa bilis ng iteration, ayaw magpahuli ng startups, tech giants, o researchers—pati na ang NVIDIA. Kaya naman, hindi lang sila nagbebenta ng “pala” o graphics card; binuo rin ng NVIDIA ang multi-billion dollar DGX Cloud supercomputer, at nag-develop ng advanced models gaya ng La Proteina (protein synthesis) at OpenFold 3. Saklaw ng open source model ecosystem ng NVIDIA ang biomedicine, Physical AI, agent models, robotics, at autonomous driving. Bilang highlight, maraming open source models mula sa NVIDIA Nemotron family ang ipinakilala. Saklaw nito ang voice, multimodal, retrieval-augmented generation, at security—at ayon kay Jensen, nangunguna ang Nemotron open source models sa maraming benchmark at ginagamit ng maraming kumpanya. Ano ang Physical AI? Dose-dosenang models ang inilunsad agad Kung ang large language models ay para sa digital world, malinaw na ang susunod na ambisyon ng NVIDIA ay dominahin ang “physical world.” Sabi ni Jensen, kailangan matutong umunawa ng AI ng physical laws at mabuhay sa totoong mundo, kung saan napaka-rare ng data. Bukod sa Nemotron agent open source models, inilatag niya ang core architecture ng Physical AI gamit ang “tatlong computer.” Training computer—ito ang karaniwang computer na may training-grade graphics cards, gaya ng GB300 architecture.
Inference computer—“cerebellum” sa robot o kotse na gumagana sa edge, para sa real-time execution.
Simulation computer—kasama ang Omniverse at Cosmos, nagbibigay ng virtual training environment para matutunan ng AI ang physical feedback.
Kaya ng Cosmos system lumikha ng napakaraming training environments para sa Physical AI Batay sa arkitekturang ito, opisyal na inilunsad ni Jensen Huang ang Alpamayo, ang pinakaunang autonomous driving model sa mundo na may kakayahang mag-isip at mag-reason. Iba ito sa tradisyunal na autonomous driving—end-to-end training ang Alpamayo. Ang breakthrough nito: nasolusyunan ang “long tail problem” ng self-driving. Sa harap ng hindi pa nakikitang complex na daan, hindi lang basta nag-eexecute ng code si Alpamayo—kaya nitong mag-reason parang tao. “Sasabihin nito kung ano’ng susunod na gagawin, at bakit iyon ang naging desisyon.” Sa demo, natural ang driving ng kotse, kaya nitong hatiin ang complex na sitwasyon at lutasin gamit ang basic common sense. Hindi lang ito demo—opisyal na inanunsyo ni Jensen na ang Mercedes CLA na may Alpamayo tech stack ay ilulunsad ngayong Q1 sa US, at kasunod sa Europe at Asia. Itinuring ng NCAP na pinakaligtas na kotse sa mundo ang modelong ito, dahil sa unique na “dual safety stack” ng NVIDIA. Kapag kulang sa kumpiyansa ang end-to-end AI, awtomatikong lilipat sa tradisyunal na safety mode para tiyak ang seguridad. Sa event, ipinakita rin ni Jensen Huang ang robot strategy ng NVIDIA. Kompetisyon ng siyam na top AI at hardware manufacturers, palawak nang palawak ang produkto, lalo na sa robotics. Ang highlighted cells ay mga bagong produkto buhat noong nakaraang taon. Lahat ng robot ay gagamit ng Jetson mini computer, matututo sa Isaac simulator sa Omniverse platform. At pinagsasama ng NVIDIA ang teknolohiyang ito sa Synopsys, Cadence, Siemens, at iba pang industrial systems. Inanyayahan ni Jensen Huang ang Boston Dynamics, Agility, at iba pang humanoid at quadruped robots sa stage—binigyang-diin niya na ang pinakamalaking robot ay mismong pabrika. Mula sa pinaka-basic, ang pangarap ng NVIDIA ay sa hinaharap, chip design, system design, at factory simulation ay pabilisin ng Physical AI ng NVIDIA. Sa event, nagpakitang-gilas pa ang Disney robots, at nagbiro si Jensen sa mga cute na robot: “Didesenyo kayo sa computer, gagawin sa computer, at bago pa maka-experience ng gravity, matetest at mava-validate na kayo sa computer.” Kung hindi mo alam na si Jensen Huang ang nagsalita, aakalain mong event ito ng isang model developer. Sa kabila ng AI bubble debate at paghina ng Moore’s Law, kailangan ni Jensen na ipakita kung ano nga ba ang kayang gawin ng AI para mapanatili ang kumpiyansa natin dito. Bukod sa pagpapakilala ng Vera Rubin AI supercomputing platform, naglaan din siya ng malaking effort sa applications at software para makita natin ang konkreto at diretsong pagbabago na pwedeng dalhin ng AI. Tulad ng sinabi niya, dati para sa virtual world ang chip nila, pero ngayon, sila mismo ang humaharap at nagpapakita—nakatutok sa physical AI, gaya ng autonomous driving at humanoid robots, para sumabak sa mas matinding kompetisyon sa totoong mundo. Dahil sa huli, kapag sumiklab ang digmaan, tuloy-tuloy ang benta ng armas. *Panghuli, narito ang easter egg na video: Dahil bitin ang oras sa CES, maraming slides si Jensen Huang na di naipakita. Kaya naman, ginawa niyang nakakatawang short film ang mga hindi naipakitang PPT. Panoorin sa ibaba⬇️ 0
0
Disclaimer: Ang nilalaman ng artikulong ito ay sumasalamin lamang sa opinyon ng author at hindi kumakatawan sa platform sa anumang kapasidad. Ang artikulong ito ay hindi nilayon na magsilbi bilang isang sanggunian para sa paggawa ng mga desisyon sa investment.
PoolX: Naka-lock para sa mga bagong token.
Hanggang 12%. Palaging naka-on, laging may airdrop.
Mag Locked na ngayon!
Baka magustuhan mo rin
ChatGPT trapiko tumigil, Google Gemini biglang tumaas
硬AI•2026/01/08 08:47
Patuloy na humihina ang Pound Sterling laban sa US Dollar habang nakatuon ang pansin sa US Non-Farm Payrolls.
101 finance•2026/01/08 08:43
Trending na balita
Higit paMga presyo ng crypto
Higit paBitcoin
BTC
$90,014.55
-2.17%
Ethereum
ETH
$3,107.81
-3.66%
Tether USDt
USDT
$0.9988
-0.02%
XRP
XRP
$2.1
-7.09%
BNB
BNB
$881.94
-3.54%
Solana
SOL
$134.68
-2.73%
USDC
USDC
$0.9998
+0.04%
TRON
TRX
$0.2953
+0.10%
Dogecoin
DOGE
$0.1429
-5.06%
Cardano
ADA
$0.3916
-5.62%
Paano magbenta ng PI
Inililista ng Bitget ang PI – Buy or sell ng PI nang mabilis sa Bitget!
Trade na ngayon
Hindi pa Bitgetter?Isang welcome pack na nagkakahalaga ng 6200 USDT para sa mga bagong Bitgetters!
Mag-sign up na