田渊栋:2025年年末総括(1)


Xinzhiyuanレポート
Xinzhiyuanレポート
【Xinzhiyuan要約】Llama 4の火消し役を務めたがリストラされ、今は自ら起業。AI業界のリーダー田渊栋が2025年のいくつかの重要な瞬間を振り返る。
最近とても忙しかったので、年末のまとめを1月1日以降に書くことにしました。どうであれ、書き始めることができて良かったです。

2025年1月末にLlama4の火消しを頼まれたとき、強化学習をずっとやってきた私は、事前に2x2のリワードマトリクスを描いて、次の4つの可能性を計算しました(当時は上層部からの大きな圧力があり、反対するのはほぼ不可能でしたが):

当時は、もし私たちが手伝いに行っても最終的にプロジェクトが成功しなくても、少なくとも全力を尽くしたと胸を張れると思っていました。しかし、残念ながら最後には計算外の第五の可能性が起き、この社会の複雑さをより深く実感しました。
それでも、この数ヶ月間の努力の中で、強化学習トレーニングのコアな課題、例えばトレーニングの安定性、トレーニングと推論のインタラクション、モデルアーキテクチャ設計、事前トレーニングと中期トレーニングの連携、長い思考チェーンのアルゴリズム、データ生成方法、後トレーニングフレームワーク設計などについて、いくつかの探求を行いました。
この経験自体が非常に重要で、私の研究の考え方にも大きな変化をもたらしました。
実際には、私は会社に10年以上いて、いつかは去らなければいけないと思っていましたが、経済的・家庭的な理由でなかなか辞められませんでした。
ここ1、2年は「会社に早くクビにしてほしい」という気持ちで発言や行動をしていて、むしろ開き直っていました。
2023年の年末、最初の長期休暇を取ったとき、ほぼ辞めるところでしたが、最終的にはサインせずに会社に残ることを選びました。実際、辞める決断は簡単ではありません。今はMetaが私に決断を助けてくれたとも言えます。
今回の波乱や今年一年の浮き沈みは、今後の小説創作にも多くの新しい素材を提供してくれました。
いわゆる「官途に恵まれず詩人に幸あり、滄桑を詠んでこそ名文となる」。人生があまりに平凡だと、面白みがないものです。2021年初め、年末の業務総括に「なぜ論文が通らなかったのか」の反省を書いたことで、Meet Mostをもらい、不合格になったような気分でした。
しかし、世の中の不公平を嘆くより、みんなの前で昇進したふりをした方が良いと思い、半年後には本当に昇進しました。そして、あの21年初めに誰にも注目されなかった仕事が、21年7月にICML Best paper honorable mentionを受賞し、表現学習分野で有名な論文となりました。
10月22日以降しばらくの間、私のあらゆる連絡手段がパンク状態で、毎日無数のメッセージやメール、そして遠隔会議や面談の招待があり、非常に多忙でした。
数週間後にやっと通常に戻りました。この2ヶ月、皆様のご心配と熱意に感謝します。当時、何か返信が遅れた場合はご容赦ください。
最終的に多くのオファーがあり、有名企業からも連絡がありましたが、最後はまだ若いうちに新たなスタートアップの共同創業者になることを決めました。詳細はまだ公開せず、しばらく静かに頑張ります。

2025年の主な方向性は、一つは大規模モデルの推論、もう一つはモデルのブラックボックスを開くことです。
2024年末に我々が発表した連続潜在空間推論(coconut、COLM’25)の研究以降、2025年にこの研究分野が盛り上がりました。みんなが強化学習や事前学習にこのアイデアをどう応用するか、トレーニングや計算効率をどう高めるかなどを探求しています。
私たちのチームはその後llamaの仕事に引き込まれて大きな力を注ぎ続けることはできませんでしたが、それでも非常に嬉しく思います。
それでも、上半期には理論分析(Reasoning by Superposition、NeurIPS‘25)という論文を発表し、連続潜在空間推論の優位性を示し、多くの注目を集めました。
また、大規模モデルの推論効率をいかに高めるかも重要です。私たちのToken Assorted(ICLR’25)は、まずVQVAEで潜在空間の離散トークンを学習し、その離散トークンとテキストトークンを混ぜて後トレーニングを行い、推論コストを減らしつつ性能を向上させました。
私たちのDeepConfは、各生成トークンの自信度を検出し、ある推論パスを早期終了させるかどうかを決定します。これにより推論に使うトークンが大幅に減りましたが、majority voteの場面ではむしろ性能が向上しました。
ThreadWeaverは並列推論の思考チェーンを作り、その上で後トレーニングを行い推論速度を上げます。また、dLLMではRLによる推論モデル(Sandwiched Policy Gradient)の訓練や、小規模モデルでの推論学習の試み(MobileLLM-R1)も行っています。
可視化・解釈性の面では、Grokking(頓悟)という方向には2年前から注目していました。以前、私は表現学習(representation learning)の分析を行い、学習のダイナミクスや表現崩壊の原因は分かりましたが、どのような表現が学ばれ、入力データの構造とどう関係し、どの程度の汎化能力を持つのかは謎のままでした。Grokkingという特徴出現の現象を分析することで、記憶から汎化への転換プロセスを明らかにでき、この謎を解くことができました。
最初は本当に難題で手がかりがありませんでした。2024年にはまずCOGS(NeurIPS‘25、詳しくは求道之人,不问寒暑(十))を発表しましたが、特定の例しか分析できず、私はあまり満足していませんでした。
一年以上の模索とGPT5との大量の対話を経て、最近のProvable Scaling Lawsの論文でかなり大きなブレイクスルーがありました。以前の線形構造(NTK)では見えなかったものを分析し、特徴出現のトレーニングダイナミクスを大まかに説明できました。分析例はまだ特殊ですが、新たな窓を開いたと言えます。詳しくは田渊栋 の想法をご覧ください。
年末のThe path not takenは私のお気に入りで、RLとSFTの挙動がなぜこれほど異なるのか、重みのレベルで初歩的な答えを示しました。
SFTは過学習や災難的忘却(catastrophic forgetting)を引き起こしますが、その表面的な原因はトレーニングデータがon-policyでないこと、深層的な原因は重みの主成分が外部データで大きく修正され、「基盤」が安定せずモデル性能が大幅に低下することです。
一方、RLはon-policyデータでトレーニングするため、重みの主成分は変わらず副成分だけが変わるので、災難的忘却を回避できます。また、変更された重みの分布も(特にbf16の量子化で)疎になります。

多くの人は可視化・解釈性や「AIがなぜそんなにうまく動くのか」という問題を重要視しませんが、私はとても重要だと思います。次の2つのシナリオを考えてみてください。
シナリオ1:もしScalingだけでAGIやASIに到達し、人類の労働価値がゼロになり、AIが巨大なブラックボックスとして全ての問題を解決してくれる時代になったら、AIをスーパーレベルの知性として常に善行させ、隠れて悪事を働かせないようにすることが急務です。この問題を解決するには可視化・解釈性が必要です。
シナリオ2:Scalingの道が最終的に行き詰まり、人類が指数関数的なリソース需要に敗北し、他の方法を探さねばならなくなったとき、「なぜモデルが有効で、どんなときに失敗するのか」を考えざるを得ません。この思考の流れの中で、再び研究に立ち戻り、可視化・解釈性がもう一つの道になります。
この2つの状況のいずれにおいても、最終的には可視化・解釈性が必要となります。たとえAIが全知全能全善の神になったとしても、人間の好奇心と探究心によって、AIがなぜうまくできるのかを研究することになるでしょう。
「ブラックボックス」とは疑念の連鎖の誕生を意味します。大規模モデル技術の爆発で、人間の平均レベルに達し、あるいは超える今、「三体」のダークフォレストのルールが、別の形で現れるかもしれません。
今のところ、トレーニング済みモデルのブラックボックスを開き、サーキット(circuit)を発見する作業は、まだ初歩的な段階です。
可視化・解釈性の本当の難しさは、第一原理、つまりモデルアーキテクチャ、勾配降下法、データそのものの固有構造から出発し、なぜモデルがこれらのデカップル・疎・低ランク・モジュール化・組み合わせ可能な特徴や回路を収束させるのか、なぜ多くの異なる説明が生まれるのか、これらの出現する構造はモデル訓練のどの超パラメータと関係し、どう関連するのか、などを説明することにあります。
私たちが勾配降下法の方程式から直接大規模モデルの特徴出現の必然性を導き出せる日が来れば、可視化・解釈性は生物的な証拠収集から物理的な原理推導へと進み、最終的に実践を指導し、次世代AIモデル設計の道を切り開くことになるでしょう。
400年前の物理学と比べると、今の私たちにはAI版のティコ(データ収集)、AI版のケプラー(仮説提案)はいますが、AI版のニュートン(原理発見)はまだいません。
その日が来るとき、きっと世界は一変するに違いありません。
免責事項:本記事の内容はあくまでも筆者の意見を反映したものであり、いかなる立場においても当プラットフォームを代表するものではありません。また、本記事は投資判断の参考となることを目的としたものではありません。
こちらもいかがですか?
ウォーレン・バフェットは誰もが知る名前ですが、グレッグ・エイベルはほとんどの人にとってあまり知られていません。バークシャーの次期CEOである彼が、自身の経歴について明かしたことはこちらです。
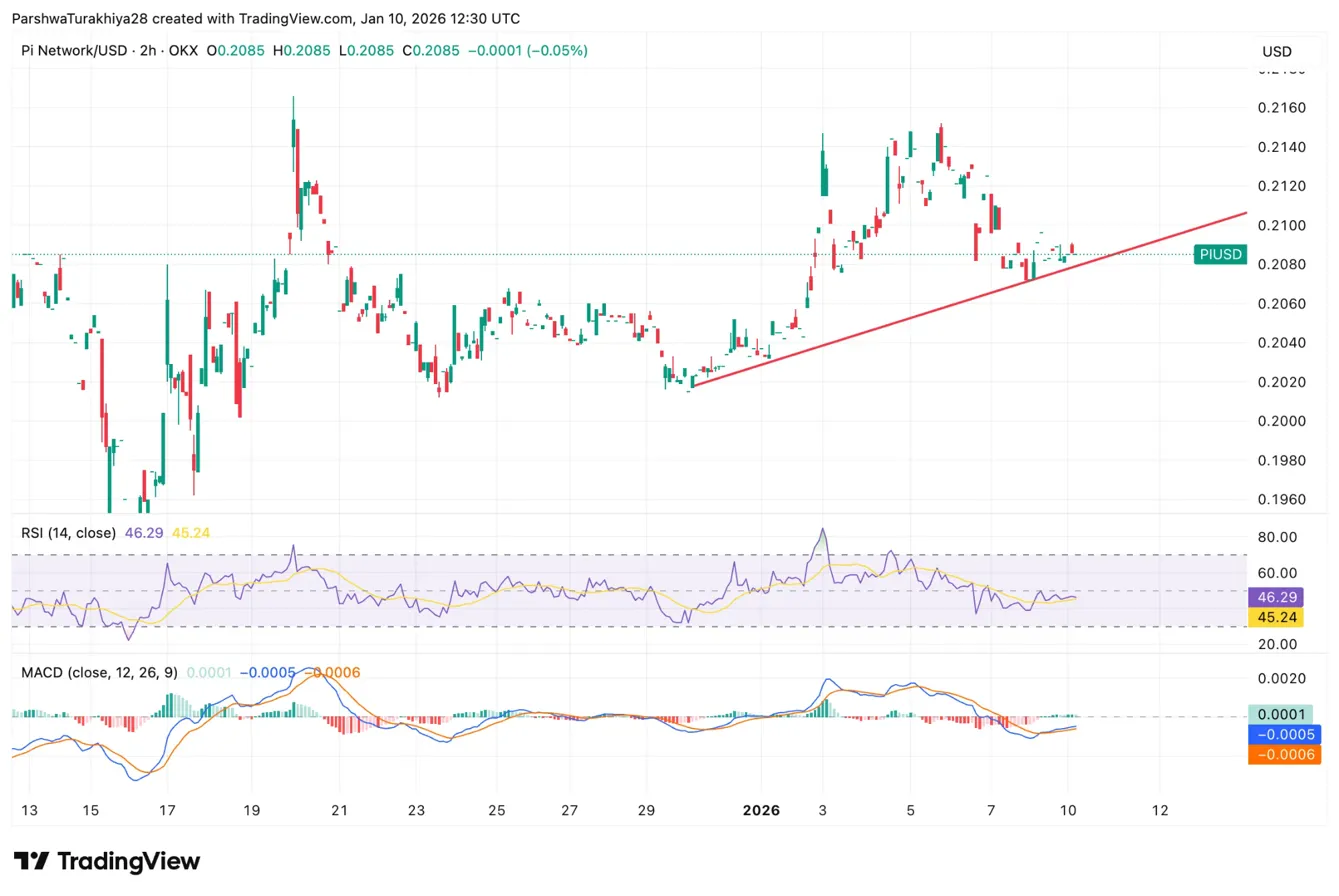
Pi Network価格予測:Developer SDKのローンチが2,000万ドルのトークンアンロックと重なり、価格はトレンドラインを維持
XRPスポットETFに記録的な資金流入、しかしアナリストは弱気発言―「開発者が十分にいない」
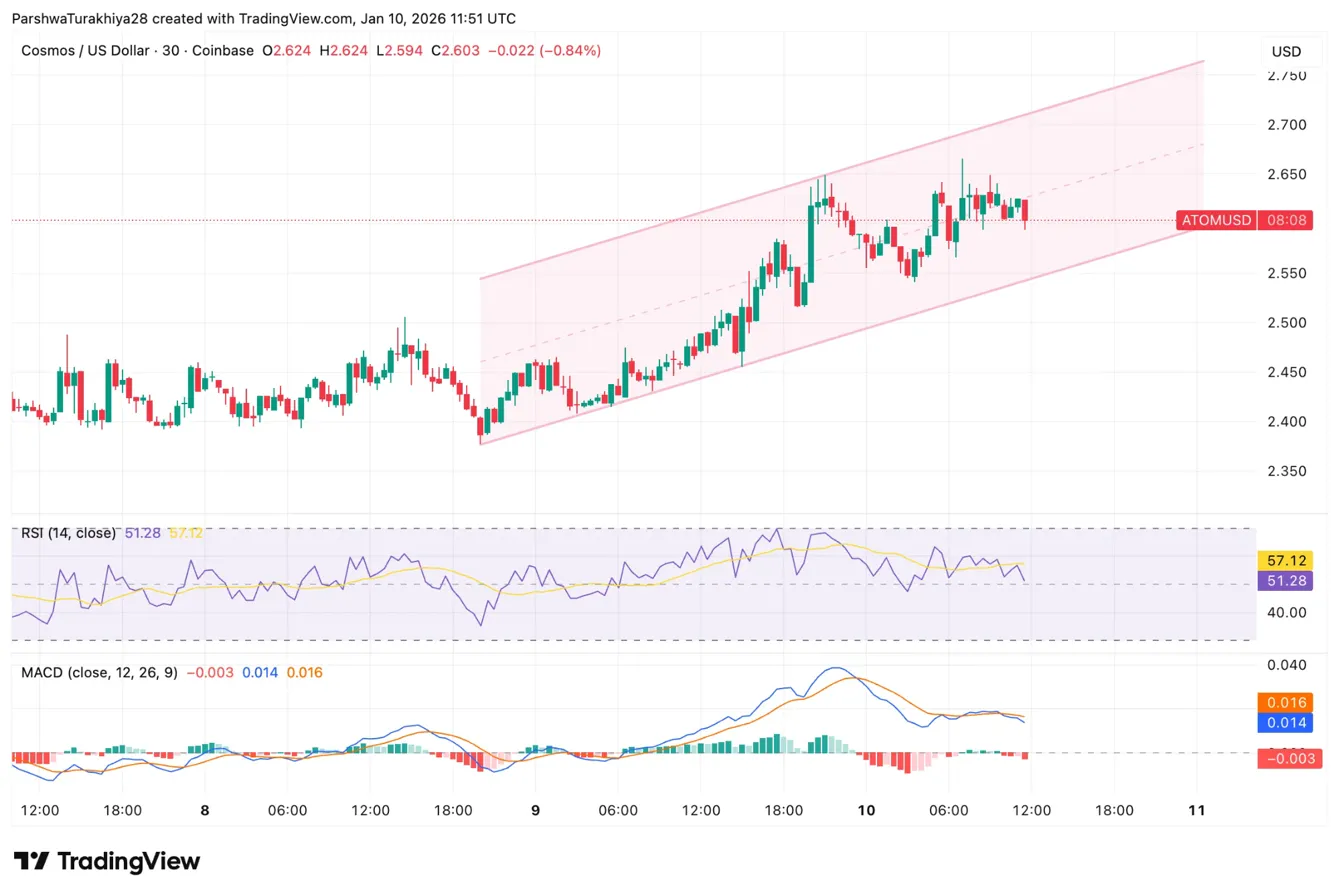
Cosmos価格予測:ATOMが18%急騰、トークノミクス改革の期限は1月15日