Nvidia stellt die neue Generation der Rubin-Plattform vor, die im Vergleich zu Blackwell die Inferenzkosten um das Zehnfache senkt und plant Auslieferungen in der zweiten Jahreshälfte.

Nvidia hat auf der CES-Messe die neue Generation der Rubin AI-Plattform vorgestellt und damit seinen jährlichen Innovationsrhythmus im Bereich der KI-Chips beibehalten. Durch das integrierte Design von sechs neuen Chips erzielt die Plattform erhebliche Fortschritte bei Inferenzkosten und Trainingseffizienz; die ersten Kundenlieferungen sind für die zweite Hälfte des Jahres 2026 geplant.

Am Montag, dem 5. (Eastern Time), erklärte Nvidia-CEO Jensen Huang in Las Vegas, dass alle sechs Rubin-Chips aus der Fertigung der Partner zurückgekehrt sind und bereits einige Schlüsseltetsts bestanden haben, so dass der Zeitplan eingehalten wird. Er betonte: "Der KI-Wettlauf hat begonnen, alle arbeiten daran, das nächste Level zu erreichen." Nvidia hob hervor, dass die Betriebskosten für Rubin-basierte Systeme niedriger ausfallen als bei der Blackwell-Version, da sie mit weniger Komponenten die gleichen Ergebnisse erzielen.
Microsoft und weitere große Cloud-Computing-Anbieter werden zu den ersten Kunden gehören, die in der zweiten Jahreshälfte die neue Hardware implementieren. Die nächste Generation der Fairwater AI Superfabrik von Microsoft wird mit Nvidias Vera Rubin NVL72 Rack-Systemen ausgestattet sein, die auf eine Skalierung auf Hunderttausende Nvidia Vera Rubin Superchips ausgelegt sind. Auch CoreWeave wird zu den ersten Anbietern von Rubin-Systemen zählen.
Die Einführung der Plattform fällt in eine Zeit, in der an der Wall Street einige Akteure eine verstärkte Konkurrenz für Nvidia erwarten und Zweifel äußern, ob die Ausgaben im KI-Sektor das derzeitige Tempo beibehalten können. Nvidia bleibt jedoch langfristig optimistisch und schätzt das Gesamtmarktvolumen auf mehrere Billionen US-Dollar.
Leistungssteigerung zielt auf neue KI-Generation ab
Laut Nvidia-Mitteilung beträgt die Trainingsleistung der Rubin-Plattform das 3,5-Fache des Vorgängers Blackwell, die Leistung beim Ausführen von KI-Software ist um das 5-Fache gesteigert. Im Vergleich zur Blackwell-Plattform kann Rubin die Kosten für die Generierung von Inferenz-Tokens um bis zu das 10-Fache senken, und die für das Training von Mixture-of-Experts-Modellen (MoE) benötigte GPU-Anzahl wird um das 4-Fache reduziert.
Die neue Plattform ist mit der Vera CPU ausgestattet, die über 88 Kerne verfügt und die doppelte Leistung vergleichbarer Produkte bietet. Diese CPU ist speziell für Inferenz-Agenten konzipiert und stellt den energieeffizientesten Prozessor für großangelegte KI-Fabriken dar. Sie basiert auf 88 maßgeschneiderten Olympus-Kernen, vollständiger Armv9.2-Kompatibilität und extrem schneller NVLink-C2C-Verbindung.
Der Rubin-GPU ist mit einer dritten Generation des Transformer-Engines ausgestattet und verfügt über hardwarebeschleunigte adaptive Komprimierungsfunktionen. Er bietet 50 Petaflops NVFP4-Rechenleistung für KI-Inferenzen. Jeder GPU bietet eine Bandbreite von 3,6 TB/s, während das Vera Rubin NVL72-Rack eine Bandbreite von 260 TB/s bietet.
Chip-Tests verlaufen reibungslos
Jensen Huang gab bekannt, dass alle sechs Rubin-Chips von den Fertigungspartnern zurückgekehrt sind und entscheidende Tests bestanden haben, die ihre planmäßige Implementierung bestätigen. Diese Aussage unterstreicht Nvidias anhaltende Führungsposition als führender Hersteller von KI-Beschleunigern.
Die Plattform umfasst fünf bahnbrechende Technologien: die sechste Generation der NVLink-Interconnect-Technologie, den Transformer-Engine, Confidential Computing, den RAS-Engine und die Vera CPU. Die Confidential-Computing-Technologie der dritten Generation macht das Vera Rubin NVL72 zum ersten Rack-Level-Plattform, das Datensicherheit über CPU-, GPU- und NVLink-Domänen hinweg bietet.
Die zweite Generation des RAS-Engine erstreckt sich über GPU, CPU und NVLink, bietet Echtzeit-Gesundheitsüberwachung, Fehlertoleranz und proaktive Wartungsfunktionen, um die Systemproduktivität zu maximieren. Das Rack verwendet ein modulares Design ohne Kabelträger, wodurch Montage und Wartung im Vergleich zu Blackwell 18-mal schneller sind.
Umfassende Unterstützung durch das Ökosystem
Nvidia gab bekannt, dass Amazon AWS, Google Cloud, Microsoft und Oracle Cloud im Jahr 2026 als Erste Instanzen auf Basis von Vera Rubin implementieren werden. Die Cloud-Partner CoreWeave, Lambda, Nebius und Nscale werden folgen.
Sam Altman, CEO von OpenAI, sagte: "Intelligenz wächst mit der Rechenleistung. Wenn wir mehr Rechenleistung hinzufügen, werden die Modelle leistungsfähiger, können schwierigere Probleme lösen und größeren Einfluss auf die Menschen haben. Die Nvidia Rubin-Plattform hilft uns, diesen Fortschritt weiter auszubauen."
Dario Amodei, Mitbegründer und CEO von Anthropic, erklärte, dass die Effizienzsteigerung der Nvidia Rubin-Plattform einen grundlegenden Fortschritt der Infrastruktur darstelle, der längere Erinnerungen, besseres Schlussfolgern und zuverlässigere Ausgaben ermögliche.
Meta-CEO Mark Zuckerberg sagte, dass Nvidias "Rubin-Plattform eine Sprungverbesserung bei Leistung und Effizienz verspricht, was notwendig ist, um die fortschrittlichsten Modelle für Milliarden von Menschen bereitzustellen".
Nvidia betonte zudem, dass Cisco, Dell, Hewlett Packard Enterprise, Lenovo und Supermicro voraussichtlich verschiedene Server auf Basis der Rubin-Produkte herausbringen werden. KI-Labore wie Anthropic, Cohere, Meta, Mistral AI, OpenAI und xAI erwarten, mit der Rubin-Plattform noch größere und leistungsfähigere Modelle trainieren zu können.
Vorzeitige Veröffentlichung von Produktdetails
Kommentare zufolge hat Nvidia dieses Jahr die Details neuer Produkte früher als sonst bekanntgegeben – eine Maßnahme, um die Abhängigkeit der Branche von der eigenen Hardware zu sichern. Normalerweise präsentiert Nvidia Produktdetails ausführlich bei der jährlich im Frühling in San Jose, Kalifornien, stattfindenden GTC.
Für Jensen Huang ist die CES nur ein weiterer Halt auf seinem „marathonartigen“ Veranstaltungsprogramm. Bei allen Gelegenheiten kündigt er Produkte, Partnerschaften und Investitionen an, um die Einführung von KI-Systemen zu beschleunigen.
Die neuen Hardware-Komponenten von Nvidia umfassen auch Netzwerk- und Verbindungsmodule, die Teil des DGX SuperPod-Supercomputers werden, aber auch separat und modular für Kunden verfügbar sein werden. Diese Leistungssteigerung ist notwendig, da sich KI auf stärker spezialisierte Modellnetzwerke verlagert, die nicht nur große Datenmengen filtern, sondern auch spezifische Probleme in mehrstufigen Prozessen lösen müssen.
Nvidia treibt KI-Anwendungen für die gesamte Wirtschaft voran, einschließlich Robotik, Gesundheitswesen und Schwerindustrie. Im Rahmen dieser Bemühungen kündigte Nvidia eine Reihe von Tools an, die die Entwicklung von autonomen Fahrzeugen und Robotern beschleunigen sollen. Der Großteil der Ausgaben für Nvidia-basierte Computer stammt derzeit aus den Investitionsbudgets weniger Großkunden, darunter Microsoft, Google Cloud von Alphabet und AWS von Amazon.

Haftungsausschluss: Der Inhalt dieses Artikels gibt ausschließlich die Meinung des Autors wieder und repräsentiert nicht die Plattform in irgendeiner Form. Dieser Artikel ist nicht dazu gedacht, als Referenz für Investitionsentscheidungen zu dienen.
Das könnte Ihnen auch gefallen
MixMax arbeitet mit Aylab zusammen, um das Wachstum und Volumen von Web3 und DeFi im Jahr 2026 zu fördern
Cardanos kühner Preissprung: ADA nimmt das 10-Dollar-Ziel ins Visier
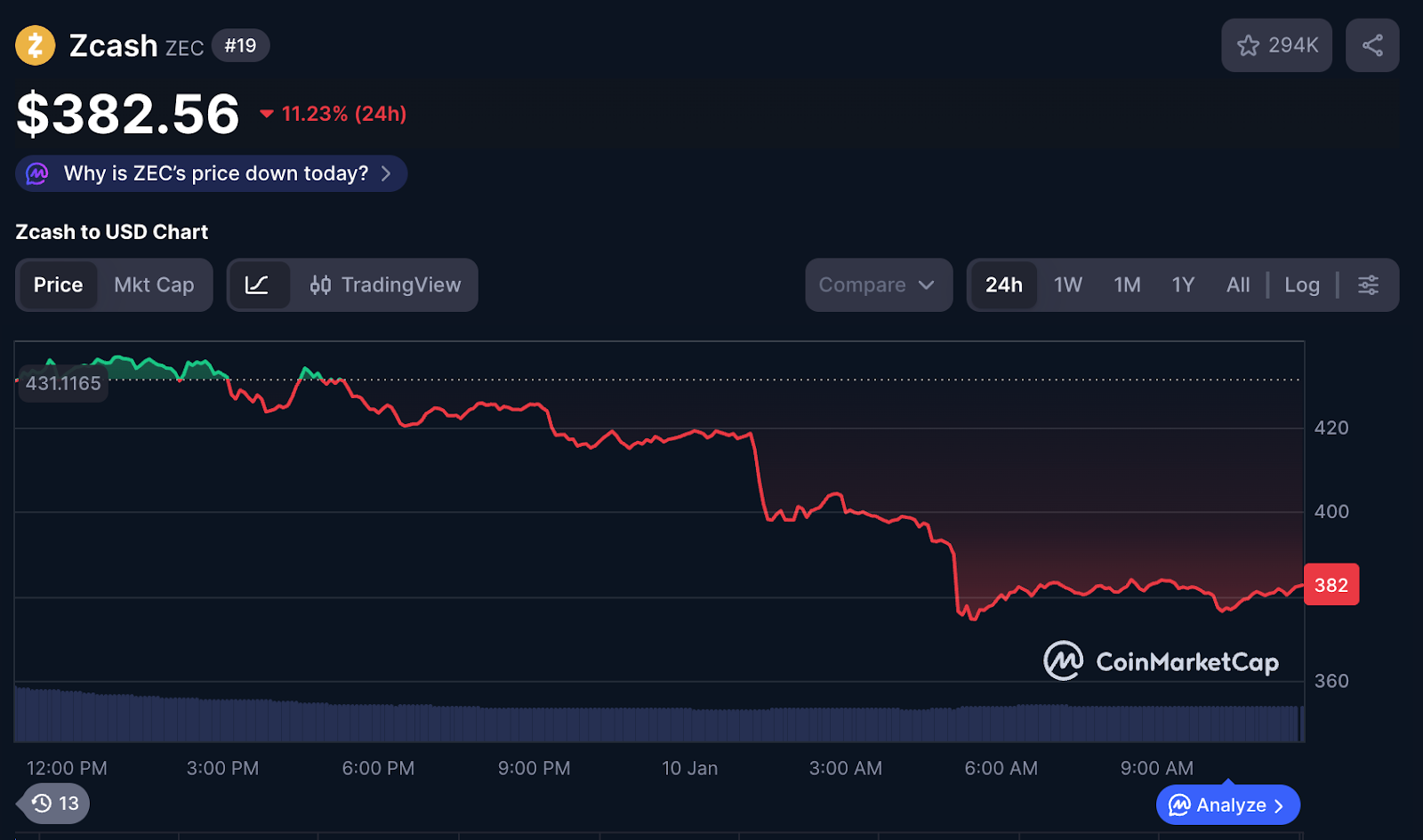
Während Zcash Schwierigkeiten hat, verzeichnen XRP und Solana institutionelle Booms